
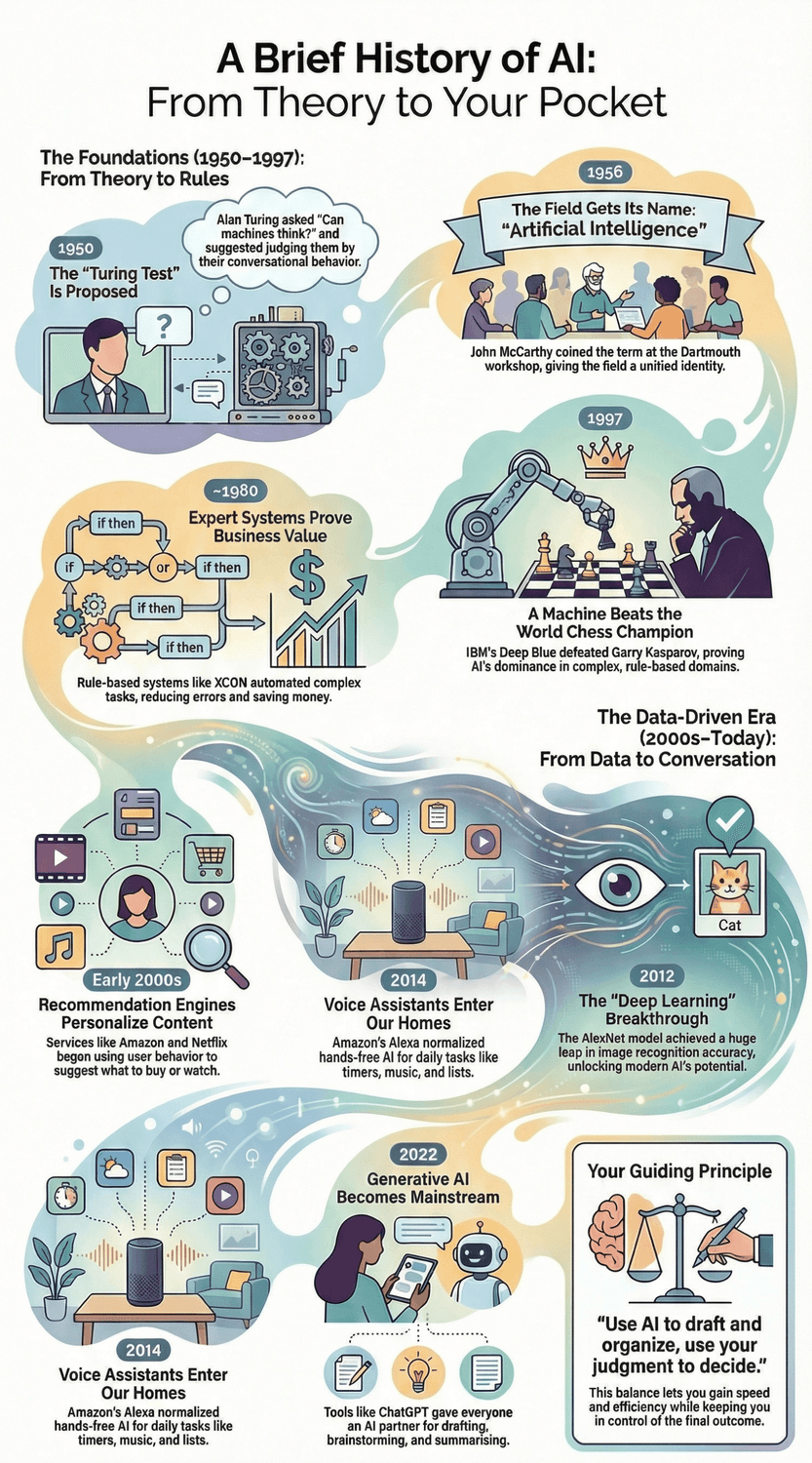
The History of AI in 10 Easy Steps
By Rado
You’ve seen AI everywhere, yet the story behind it feels fuzzy. Here’s the short version: ten key moments that show how we moved from big ideas to everyday helpers you can use with confidence. We’ll keep it plain, practical, and focused on what each step unlocked for real life.
🎧 Prefer to Listen Instead of Read?
Deep Dive into the Podcast Version of this Blog
📺 Watch the Explainer Version of this Blog on YouTube
1) What kicked off the idea of “thinking machines”? (1950)
Picture yourself at the kitchen table, asking a bank’s chat assistant a tricky question about a transfer. It replies quickly, but does it understand you or just follow patterns? That simple doubt is where the field began.
In 1950, Alan Turing posed a plain question: Can machines think? Then he sidestepped the vague wording and suggested a practical check he called the “imitation game,” now known as the Turing Test. Instead of debating definitions, Turing proposed we judge by behavior: if a machine’s answers are indistinguishable from a human’s in a text chat, we count that as intelligence for the purpose of the test. You can read the original paper here Turing (1950) and a clear plain‑English overview in the Stanford Encyclopedia of Philosophy (2003).
You might be wondering, why start with a test instead of a blueprint? Because tests give everyday people a handle. Could you tell the difference in a blind chat? Would your follow‑up questions reveal a crack? It’s normal to feel unsure about what “intelligence” means. Turing’s move lets you focus on outcomes you can experience: helpful answers, consistent reasoning, and the ability to handle clarifying questions.
Here’s the short version. Turing turned philosophy into a practical experiment. He also anticipated common objections: what if the machine just imitates without understanding? What about creativity, emotion, or mistakes? These are still fair questions. In your own life, you can use a Turing‑style mindset with any AI app: ask layered questions, vary the context, and see if the answers stay coherent.
So, what matters to you today? First, the idea of behavioral evaluation. You don’t need to peek under the hood to decide if a tool is useful. Second, the limits of the test. Passing a chat exchange doesn’t mean a system understands like a person. It might still miss context, assume facts, or make confident errors. Third, the role of your judgment. If a response sounds smooth but stakes are high, verify with a trusted source or a human expert.
Two quick examples you can try this week: planning a train trip and checking a medical bill. For the trip, ask an AI to sketch the route, then change dates, add a stop, and ask about senior discounts. Does it adapt? For the bill, request a plain‑language summary, then ask it to point to the exact line items. Does it show its work? These mini‑tests will tell you more than any hype.
The Key Takeaway
Turing’s question gave us a simple habit that still works.
Judge AI by how well it holds up in your real conversations, then double‑check important details before you act.
2) When did AI become a formal field? (1956)
Imagine you are sorting apps on your phone. Until you make folders, everything feels scattered. The moment you name a folder, things click. That is what 1956 did for AI.
In the summer of 1956, a small group of researchers met at Dartmouth College for a focused workshop. Computer scientist John McCarthy suggested a simple, powerful label: Artificial Intelligence. With a shared name, scattered efforts suddenly had a common home. Funding conversations got easier. Research goals became clearer. And newcomers could finally say, “I work in AI,” instead of listing a dozen separate topics.
You might be wondering why a name matters so much. It is normal to feel that results should matter more than labels. But names help you ask better questions. When you search your bank app for help or set up a smart speaker, you can now place it under one mental folder: AI. That makes comparison easier. It also helps you notice differences. Is this tool rule based? Does it learn from data? Does it create new content? Clear categories help you pick the right tool for the job.
Here is the short version. The Dartmouth workshop joined ideas from logic, language, vision, and learning under one umbrella. The goal was ambitious: make machines do tasks that require intelligence when done by people. The energy was high, and expectations were bold. Progress turned out to be slower than hoped, which led to cycles of excitement and disappointment. That pattern still shows up today, which is why patience and basic evaluation skills matter.
Two practical tips for your day to day. First, read the product page of any AI tool and look for the category signal. Is it built on rules, statistics, or neural networks? Second, scan for what data it needs. Does it use your documents, your voice, or your browsing history? Knowing the category and the data helps you judge risk and reward.
Want a quick credibility check? If a tool claims to do “everything,” treat it like a red flag. Ask focused questions. What tasks does it handle best? How does it learn? Can it explain a decision? These simple prompts often separate mature tools from noisy ones. It is a fair question to ask, and good companies will answer in plain language.
If you would like to read more background, the Britannica overview of artificial intelligence gives a clean timeline from early logic to modern systems, and the Stanford HAI timeline summarizes key milestones, including the Dartmouth moment. Both are friendly, high level resources.
The Key Takeaway
1956 gave AI a name and a shared room. Use that same clarity today.
Name the kind of system you are using and the data it relies on, then decide how and where it fits your life.

3) When did computers first seem to “talk back”? (mid‑1960s)
You open a support chat to fix a travel booking. The agent echoes your words and asks, “How does that make you feel?” Helpful or hollow? That uneasy feeling traces back to one early program.
In the mid‑1960s, MIT researcher Joseph Weizenbaum built ELIZA, a simple conversation simulator that used pattern matching and templates to reflect a user’s words back, especially in its famous “DOCTOR” script. Ask, “I’m worried about my job,” and it might reply, “Why are you worried about your job?” On paper, it was modest. In practice, many people felt they were being understood. Weizenbaum later described this effect and his concerns about over‑trust in his writings, including the original 1966 paper and later reflections covered in Britannica’s overview.
You might be wondering, how could such a simple program feel so convincing? It is normal to expect “intelligence” to require deep reasoning. ELIZA shows that good mirroring can go a long way in short chats. The system searched your sentence for cues, then used a canned response pattern. No understanding of meaning. No memory across topics. Just clever echoing. Yet the experience was striking enough to launch debates about empathy, ethics, and where to draw the line between simulation and understanding.
Here is the short version. ELIZA was a proof of interface, not a proof of intelligence. It revealed how tone, pacing, and phrasing shape our trust. It also gave a first look at chat as a user interface, which is now central to how we use AI at home and at work. The lesson endures: fluency can mask limits. Smooth sentences do not guarantee correct facts or sound judgment.
So what do you do with that insight today? First, treat polished wording as a starting point, not the finish line. Ask for specifics: “Show me the steps,” “Cite the source,” or “What could go wrong?” Second, probe for memory and reasoning. Change a detail, add a constraint, or ask the tool to explain its choice. Does it keep track, or does it drift? Third, set boundaries for sensitive topics. If a reply feels confident but the decision is medical, legal, or financial, slow down and verify.
A quick kitchen‑table test you can run this week: pick a mundane task like comparing two phone plans. Ask a chatbot for pros and cons. Then ask it to create a 100‑euro budget for calls and data and to flag any hidden fees. Finally, ask where each claim comes from. Do the answers stay consistent? Do the sources check out? It is a simple way to separate friendly chat from reliable help.
For more background, MIT’s historic accounts and Britannica on ELIZA provide accessible summaries. If you enjoy primary sources, start with Weizenbaum (1966).
The Key Takeaway
ELIZA taught us that conversation can feel smart.
Your job is to look past the polish.
Ask for details, test for memory, and verify anything important before you act.
4) How did AI prove real business value? (around 1980)
Picture an office in the early 80s. A sales rep needs to configure a complex computer order with dozens of choices. Before lunch. One wrong pick and the system will not work. Who do they ask? In many companies, the answer became an expert system.
By the late 1970s and early 1980s, expert systems tried to capture the judgment of human specialists in a set of if‑then rules. The famous example was XCON at Digital Equipment Corporation, built to configure VAX computers. It encoded thousands of rules to check compatibility and suggest the right parts. Reports at the time credited XCON with saving time and reducing costly errors in orders. For a friendly primer on expert systems, see Britannica’s overview (n.d.), and for background on XCON, see the short histories collected by Stanford HAI (2024) and retrospectives linked from CMU’s AI pages.
You might be wondering, how can a pile of rules replace a seasoned pro? It is normal to feel skeptical. Expert systems worked best in narrow, well‑structured domains where experts agreed on the steps. Think of it like a very strict checklist with smart branching. When the problem stayed inside that box, results were strong. When the real world shifted or the rules did not cover an edge case, performance dropped.
Here is the short version. Expert systems proved that AI could deliver measurable business value: fewer mistakes, faster quotes, and consistent decisions. They also revealed two limits you still see today. First, knowledge capture is hard. Extracting rules from experts takes time, and busy teams often disagree on the “right” rule. Second, maintenance matters. As products change, rules drift out of date unless someone owns the updates. Britannica’s entry notes both the promise and the maintenance challenge Britannica, n.d..
What does this mean for you now? Many reliable systems you use every day still combine rules with learning. Bank fraud checks, website forms that validate details, and help‑desk flows all rely on clear decision paths. When you evaluate a modern tool, ask two simple questions. Is the task repetitive and high‑stakes? If yes, rules may be safer. Does the task involve fuzzy judgment or changing patterns? If yes, a learning system may adapt better, but you will want audit trails and human review.
Practical tip for your week. Open a product you already use, like your email filter or a form builder. Try to spot the rules it follows. Then ask, where would a learning approach help? Could it auto‑categorize messages more accurately if you gave feedback? Could it suggest form fields based on past entries? This small exercise trains your eye to match the method to the job.
If you enjoy digging deeper, the Stanford HAI timeline (2024) sketches how expert systems fit into the broader arc, and Britannica gives a clean summary of strengths and weaknesses Britannica, n.d..
The Key Takeaway
Expert systems showed AI can pay its way when the rules are clear and the stakes are real.
Start with narrow, stable tasks, set an owner for updates, and keep humans in the loop for exceptions.
5) When did a machine beat a world champion? (1997)
Think of a weekend chess app on your phone. You play a decent game, then it finds a quiet move you never saw coming. Now scale that feeling up to the world champion across a real board, under TV lights, with the whole world watching.
In May 1997, IBM’s Deep Blue defeated Garry Kasparov, the reigning world chess champion, in a six‑game match. Deep Blue did not “think” like a person. It evaluated around 200 million positions per second and used carefully crafted search algorithms with expert‑encoded evaluation functions. The result was historic and widely reported by outlets like The New York Times (1997) and summarized clearly by Britannica and IBM Research’s Deep Blue page.
You might be wondering, what did this victory actually prove? It is normal to feel that chess is special and may not reflect everyday life. Deep Blue showed that narrow AI can dominate a well‑defined problem when you combine speed, search, and domain knowledge. That does not mean it understands like a person, or that it can handle messy, open‑ended tasks. It does mean that for some jobs, brute force plus smart pruning can beat expert intuition.
Here is the short version. The match highlighted three lessons that still matter. First, define the game. Chess has clear rules and a finite board, which makes it ideal for computation. Second, engineering counts. Hardware acceleration, clean software, and expert insights into position evaluation all tipped the scales. Third, victory in one domain does not generalize by default. A chess engine is great at chess and not much else. As Stanford HAI’s timeline notes, later breakthroughs moved from search‑heavy systems to learning‑driven ones.

So what does this mean for you today? When you see a tool that claims “expert level” performance, ask yourself three questions. Is the task tightly bounded with firm rules? If yes, machines may shine. Does the tool rely on speed and search or on learning from examples? Each path has strengths and weaknesses. What happens when the rules shift? Real life often changes faster than a chessboard, so look for update plans and human oversight.
Practical ways to use this mindset at home or at work. For structured tasks like scheduling, document formatting, or price comparisons inside set rules, let automation lead. For fuzzy tasks like resolving a customer dispute or weighing trade‑offs in a budget, keep a human in the loop and ask AI to generate options, not final decisions. It is a fair balance that respects what each side does best.
If you want to go deeper, IBM’s official history is a quick read (IBM Research), and Britannica captures the core facts and impact (Britannica).
The Key Takeaway
Deep Blue proved that machines can dominate a clear, rule‑based domain.
Use AI where the rules are crisp and the search space is big, and use your judgment where context and values matter most.
6) What made our media feel “picked just for me”? (early 2000s)
You open a streaming app after dinner. One tile looks perfect. Same actor you like, similar tone, and a weekend‑friendly length. You did not hunt for it. It found you. That feeling has a history.
In the early 2000s, recommendation systems moved from research labs into everyday products. Retailers and media platforms began using your clicks, ratings, and purchases to predict what you would likely want next. A key milestone was Amazon’s item‑to‑item collaborative filtering, which compared products rather than people to deliver fast, scalable suggestions.
If you bought Book A, and many others who bought Book A also bought Book B, the system would surface Book B to you. Amazon engineers described the method in Linden, Smith, & York (2003). A few years later, Netflix fueled rapid progress by opening its data contest, the Netflix Prize (2006), which spurred new blending and matrix‑factorization techniques that improved accuracy on movie ratings.
You might be wondering, why do these systems feel so good when they are just math on past behavior? It is normal to feel a mix of delight and doubt. Recommenders work because they lower the cost of choice.
Instead of scanning thousands of options, you get a short list tuned to your taste. At the same time, they can create filter bubbles or anchor you to more of the same. Both things can be true. The win is convenience. The risk is narrowing over time if you never step outside the lane.
Here is the short version. Early recommenders learned two core lessons that still matter today. First, behavior beats biography. What you do is a better signal than who you are. Second, simple models at scale can outperform fancy ones if they run quickly and update often. Netflix’s open challenge and later blog posts show how combining different approaches often wins, even when each on its own is modest Netflix Prize (2006).

So, what can you do with this at home? Three practical habits. First, tune your signals. Rate items, remove stale watchlist entries, and click “Not interested.” Your feedback is steering. Second, break the bubble on purpose. Once a week, search for something entirely different. New signals lead to fresher picks. Third, check privacy settings. Decide which data sources your apps can use. Some services let you turn off cross‑app tracking or ad personalization. That is a fair boundary to set.
A quick kitchen‑table test you can try this week. Open your favorite shop or streaming service and look for a “Because you watched” or “Customers also bought” row. Ask yourself three questions. Does it reflect what you actually enjoyed? Does it include at least one surprise that could widen your taste? Can you see or edit the feedback it uses? Small questions like these keep you in the driver’s seat.
For a friendly overview of how recommenders evolved and why they matter, see Britannica on Recommender Systems. For a primary source on the retail side, start with Linden et al. (2003), and for the media side, the Netflix Prize page captures the period when public competition accelerated progress.
The Key Takeaway
Personalization rose because simple, data‑driven suggestions saved you time.
Use your ratings to guide it, poke holes in the bubble now and then, and keep your privacy choices tight.
7) Did AI master language trivia too? (2011)
Picture a family quiz night. You are quick with facts, but the clues come fast and the wording is tricky. Now imagine doing that against champions on TV, with a buzzer, and categories that jump from Shakespeare to U.S. cities in seconds. Could a computer keep up?
In February 2011, IBM Watson faced Jeopardy! legends Ken Jennings and Brad Rutter. Watson parsed the clues, searched vast text collections, weighed candidate answers, and buzzed only when its confidence was high. It won decisively, a moment widely chronicled by IBM Research and explained in plain terms by Britannica. The system combined natural language processing, information retrieval, and statistical models to turn messy questions into likely answers within seconds.
You might be wondering, does winning a quiz show mean it “understands” language? It is normal to feel unsure. Watson showed that machines can parse and retrieve across noisy text, score alternatives, and manage timing. It did not show human‑style comprehension or common sense. Like Deep Blue before it, this was a victory in a narrow arena with clear rules and lots of engineering.
Here is the short version. The Jeopardy! match delivered three lasting lessons. First, speed plus confidence control matters. Watson did not answer every clue. It buzzed when the odds favored it. Second, data coverage counts. The system drew on encyclopedias, news archives, and reference works, which helped on unfamiliar topics. Third, presentation can mislead. A smooth answer sounds smart, but the internal process is closer to ranked retrieval than to human reasoning. As Stanford HAI’s timeline notes, later systems shifted toward deep learning that learns patterns directly from data.
So what can you take from this for daily life? Think about your email or notes. When you search, you want the right snippet quickly, not a lecture. Modern tools borrow this spirit: parse the question, fetch likely sources, and rank the results. Your part is to set the question well and check the source. If a reply feels confident, ask, “Where did this come from?” and “Can you show the exact line?” Those are fair requests.
Two quick exercises you can try this week. First, give an AI a tricky, pun‑like question you might hear on a quiz show, then ask it to explain why its answer fits each word in the clue. Does it show its steps or just state an answer? Second, ask it to pull a fact from a specific document you provide. Can it find and quote the line, or does it drift into guesswork? These small tests sharpen your trust meter.
If you are curious about the build, IBM’s write‑ups describe the architecture and the post‑Jeopardy applications in healthcare and business search IBM Research. For a neutral summary, see Britannica’s entry on Watson.
The Key Takeaway
Watson proved that fast parsing and ranked retrieval can beat humans on buzzer‑driven trivia.
Use the same idea at home.
Ask clear questions, look for sources, and prefer tools that show their work.
8) What unlocked today’s boom in accuracy? (2012)
You sort old travel photos. Your phone suddenly recognizes your spouse and friends without you tagging them. That “how did it know?” moment traces back to a turning point in 2012.
In 2012, a deep neural network named AlexNet blew past previous records on the ImageNet image‑recognition challenge. Trained on millions of labeled photos and accelerated by graphics processors (GPUs), it cut the top‑5 error rate by a large margin compared with older methods. This result, described in Krizhevsky, Sutskever, & Hinton (2012) and summarized by Stanford HAI’s timeline, kicked off a wave of advances across vision, speech recognition, translation, and later, language modeling.
You might be wondering, why did accuracy jump so quickly? Three ingredients came together. First, data: ImageNet offered a massive, well‑labeled dataset covering thousands of object categories. Second, compute: affordable GPUs let networks train in days instead of months. Third, architecture and tricks: convolutional layers, ReLUs, dropout, and data augmentation improved learning and reduced overfitting. None of these alone were brand‑new, but together they crossed a threshold.
Here is the short version. Deep learning scales. Give it more data and compute, and performance often improves without hand‑crafting features. That scaling property later powered speech‑to‑text that understands accents better, photo search that actually finds the picture you meant, and machine translation that feels smoother. Accuracy does not equal understanding, but it does make tools far more useful in daily life.

So what does this mean for you now? When a product claims “AI‑powered accuracy,” ask two questions. What data was it trained on? Broad, high‑quality data tends to travel well; narrow data may overfit. How does it fail? Look for confusion cases (poor lighting, unusual phrasing, niche topics) and whether you can correct errors with feedback. It is normal to expect occasional misses. The key is whether the system learns and whether you can spot its limits.
A practical exercise this week. Test your phone’s voice dictation in a noisy kitchen, then again in a quiet room. Does it adapt? Try your photo app’s search with a specific query like “red umbrella 2019.” If it stumbles, add a word or two. Small tests like these help you see the strengths and edges of deep learning in your own tools.
For primary sources and friendly summaries, start with Krizhevsky et al. (2012) and the Stanford HAI timeline. For a general audience recap of why ImageNet mattered, Britannica’s deep learning entry is a clear read.
The Key Takeaway
2012 showed that deep learning, fed by data and GPUs, can leap in accuracy.
Use it where precision helps (speech, photos, translation) and keep an eye on failure modes so you can step in when it slips.
9) When did voice assistants move into our homes? (2008–2014)
You are cooking dinner with messy hands. “Timer for ten minutes,” you say into the air. It starts. No taps, no scrolling. That small convenience tells a bigger story.
In the late 2000s, speech recognition improved enough to power everyday tools. Google Voice Search arrived on smartphones in 2008, bringing simple voice queries to the mainstream. A few years later, Apple introduced Siri on the iPhone 4S in 2011 after acquiring the SRI project and wrapping it in a friendly, on‑device assistant Apple, 2011. Then Amazon launched Echo with Alexa in 2014, putting a far‑field microphone in the living room and normalizing hands‑free requests Amazon, 2014. Together, these steps shifted voice from a novelty to a habit.
You might be wondering, why did voice click then, not earlier? It is normal to think the idea was always obvious. Three ingredients lined up. First, accuracy rose thanks to data and better acoustic models. Second, microphones improved, so devices could hear you from across the room. Third, cloud services matured, so assistants could fetch weather, music, and calendars in seconds. When the path from request to result got short enough, people adopted the habit.
Here is the short version. Voice assistants made natural interfaces normal. Ask for a song, set reminders, add milk to a list, or turn on a lamp without pulling out a phone. That matters for accessibility as well as convenience. At the same time, it raised new questions about privacy. Always‑listening devices collect audio triggers and usage logs, which is why settings and mute buttons are worth learning.
So how should you think about voice tools today? Start with simple, low‑risk jobs. Timers, lists, weather, music, and smart plugs are painless wins. For anything personal, like banking or health details, prefer your phone with screen confirmation. It is a fair boundary that keeps you in control. Also check which skills or integrations are enabled. Do you want shopping by voice active? If not, turn it off.
Two quick kitchen‑table tests for this week. First, ask your assistant to add two items to a list, then ask it to read the list back. Does it keep both items in the right order? Second, set three timers with different names, then cancel one. Does it follow you? Small tests like these show whether the assistant handles context or just single commands.
For friendly overviews and timelines, Britannica has accessible entries on speech recognition and virtual assistants. For primary milestones, see Apple’s 2011 Siri launch and Amazon’s Echo and Alexa background.
The Key Takeaway
Voice became useful when accuracy, microphones, and cloud apps came together.
Use it for quick, low‑stakes tasks, learn the privacy settings, and keep sensitive actions on screens where you can confirm details.
10) When did generative AI hit the mainstream? (2022 → now)
You sit down to write a tricky email. A blank page stares back. You ask an AI helper for a first draft. Ten seconds later, you are editing instead of starting from scratch. That shift from “stuck” to “moving” is why this step matters.
Late 2022 is when generative AI landed in everyday life. ChatGPT made conversational help widely accessible, turning natural language into a practical interface for brainstorming, drafting, and tutoring. Around the same time, image tools such as DALL·E 2, Stable Diffusion, and Midjourney showed how a short prompt could create pictures, logos, and concept art. These tools built on years of progress in deep learning, transformer models, and diffusion methods, but the change you felt was simple: friendly access in the browser and results that felt useful within minutes.
You might be wondering, does this mean AI finally “understands” us? It is normal to feel both amazed and cautious. Generative systems are excellent at patterned creation and language fluency. They still make mistakes, fill gaps with guesses, and reflect the limits of their training data. That is why your judgment, prompts, and simple checks are part of the workflow, especially for health, money, legal matters, or anything that affects other people.
Here is the short version. Three forces pushed gen‑AI into the mainstream. First, access. No special setup, just a web page or an app. Second, versatility. One tool can outline a lesson, reword a paragraph, plan a weekend, and draft a complaint letter. Third, ecosystems. Copilots arrived inside email, documents, browsers, and coding editors, so help shows up where you already work. When help is close to the task, you use it more.
So how can you get steady value without drama? A simple playbook works. Start small with low‑risk jobs like rewriting a paragraph for clarity, summarizing a meeting note, or planning a two‑stop day trip. Keep context tight. Paste the relevant text and ask for exactly what you need in one or two sentences. Verify important claims with a trusted source or a colleague. Protect sensitive data by removing names, account numbers, or private details before you paste. These steps are boring by design. Boring keeps you safe.
Two quick kitchen‑table exercises for this week. First, ask an AI to outline a short how‑to guide, then say, “Cite two public sources and link them.” Do the links exist and match the statements? Second, paste a rough paragraph from an email or blog draft and ask for two rewrites: one warm and concise, one formal and precise. Which fits your voice? It is a fair way to test range without risk.
If you would like friendly primers, try Britannica’s summaries of transformers and generative AI, or Stanford HAI’s timeline for the broader arc. For product histories, the official announcement pages for ChatGPT, DALL·E 2, and Stable Diffusion explain the goals and guardrails in plain language.
The Key Takeaway
Generative AI went mainstream when access, versatility, and built‑in copilots came together.
Use it to draft, plan, and learn faster, keep sensitive data out of prompts, and verify anything that matters before you act.

So what does this timeline mean for you?
You are planning a weekend trip. Ten tabs open. A friend says, “Ask the AI to sketch the plan.” You try it. Now you are reviewing options instead of juggling windows. That small shift—idea to draft—captures the value of each milestone above.
Across seven decades, the pattern is steady: AI moves from theory to useful habits. Turing taught us to judge by behavior. Dartmouth gave us a clear name. ELIZA revealed how chat can feel smart. Expert systems proved that rules can pay their way. Deep Blue showed that narrow excellence is possible. Recommenders made choice easier. Watson mixed speed with sources. Deep learning raised accuracy across tasks. Voice assistants kept help close at hand. Generative tools put drafting and re‑phrasing in everyone’s reach.
You might be wondering, where should you start—or improve? It is normal to feel a bit overwhelmed. Here is a simple map aligned to everyday moments:
Writing & email: Ask for a first draft or a clearer rewrite, then edit with your judgment. Keep private details out.
Planning & decisions: List your constraints (budget, time, preferences) and ask for 2–3 options. Compare, then verify dates and costs.
Learning: Request a plain‑language explanation with one analogy and one example. If stakes are high (health, money, legal), consult a pro.
Photos & voice: Use built‑in tools for search and dictation to save time. Test in noisy or low‑light settings to know the limits.
Safety: Turn on two‑factor login, review data permissions, and verify links or bills with official sources.
A quick weekly habit that compounds: five‑minute “mini‑tests.” Pick one task, try an AI helper, then note what worked and what did not. Ask, “Did it save me time?” and “Where did I need to step in?” Small experiments build skills without risk.
If you want a one‑line rule to carry forward, try this: Use AI to draft and organize, use your judgment to decide. That balance keeps the benefits and trims the risks.
The Key Takeaway
The timeline is not about machines replacing people.
It is about tools getting closer to how you think and work.
Start with low‑risk tasks, set your boundaries, and let AI handle the heavy lifting while you keep the wheel.

To conclude...
You have just walked the short path from Turing’s question to the tools on your phone. The pattern is simple. Each milestone brought AI a step closer to daily life: rules that reduced errors, search that won on speed, deep learning that raised accuracy, and now conversational tools that help you draft, plan, and learn. Use AI where it saves time and fits your values. Keep private data out, check important facts, and let your judgment be the final step.
If you want a single habit to keep: ask for a first draft, then verify. That rhythm gives you speed without losing control. For deeper reading on key moments, see the short histories from Stanford HAI and Britannica.
The Journey of AI (Free PDF to Download)

🎓 Your "Tech Dignity" Toolkit
Ready to stop surviving the AI era and start owning it? I’ve built a library of resources specifically designed to help you stay safe, stay professional, and stay in control. Whether you want to fix a specific problem or master the whole machine, start here:
[FREE] The "Bypass the Bot" Bundle: Stop screaming at automated phone menus. Get the secret codes and scripts to reach a human every time. Download for FREE Here
Secure Your Family: Protect your loved ones from AI voice clones and deepfake scams with the Family Shield Anti-Scam Kit. Get Protected for $9
Upgrade Your Career: Use my "Strategy Sandwich" method to delegate grunt work to AI while keeping your professional edge with the Executive Director’s AI Workflow. Reclaim Your Time Here
Lock Down Your Privacy: Interrogate the "black box" and secure your data with the AI Truth & Privacy Protocol. Secure Your Data Here
Tame the Machine: Strip the "creepy" fake empathy out of AI and turn it into a silent tool with the "Strictly Business" AI Tuner. Take Control Here
The Ultimate Shortcut: Want the entire library? Secure your digital future with the Complete Mastery Collection (all products bundled for about 57% off). Get the Full Collection Here
Frequently Asked Questions
Q1) What is the Turing Test and should I use it at home?
The Turing Test (Turing, 1950) is a thought experiment that judges intelligence by behavior in a text chat. At home, borrow the spirit, not the setup. Ask layered questions and see if the tool stays coherent. If the stakes are high, verify with a trusted source. Read a plain‑English overview in the Stanford Encyclopedia of Philosophy.
Q2) Why did progress stall after the early hype?
Early optimism met hard problems like limited computing power, small datasets, and the cost of maintaining rule sets. This led to “AI winters” where funding cooled. Momentum returned as data and GPUs grew and deep learning began to scale Britannica.
Q3) What is the real difference between rules and learning?
Rules encode expert steps (“if this, then that”). Learning finds patterns from examples. Rules shine when the domain is stable and well defined. Learning adapts when patterns shift, but you still need oversight and feedback. A classic rule win was XCON for computer configuration Britannica.
Q4) Did Deep Blue and Watson mean machines “understand” us?
They were victories in narrow arenas. Deep Blue searched chess positions very fast. Watson parsed clues and ranked likely answers. Impressive engineering, not human‑style understanding IBM Research, IBM Watson.
Q5) Why did accuracy jump around 2012?
ImageNet offered a very large labeled dataset, GPUs made training fast, and architectures like convolutional networks learned features directly from data. AlexNet’s result kicked off advances in vision, speech, and translation Krizhevsky et al., 2012.
Q6) Are voice assistants safe to use?
They are fine for low‑risk tasks like timers and shopping lists. Learn the privacy settings, disable purchases if you prefer, and keep banking or health tasks on screens where you can confirm details Apple, 2011, Amazon.
Q7) What is “generative AI” in plain terms?
Systems that create new text, images, audio, or code based on learned patterns. They are great for first drafts and re‑phrasings. They can still make mistakes, so keep sensitive data out and double‑check important facts. Britannica and Stanford HAI offer friendly primers on transformers and gen‑AI.
Q8) How can adults 45+ get practical value without risk?
Start small: rewrite a paragraph for clarity, summarize a meeting note, or plan a two‑stop trip. Keep context tight, verify dates and prices, and save private details for secure channels. This gives you the benefits while staying in control.
Sources
Turing — Computing Machinery and Intelligence (1950).
Stanford Encyclopedia of Philosophy — The Turing Test (2003).
Stanford HAI — History of Artificial Intelligence (2024).
Britannica — Artificial intelligence (n.d.).
Britannica — ELIZA (n.d.).
Weizenbaum — ELIZA: A Computer Program for the Study of Natural Language Communication (1966).
Britannica — Expert system (n.d.).
IBM — Deep Blue (1997).
Britannica — Deep Blue (n.d.).
IBM Research — Watson (2011).
Britannica — Watson (n.d.).
Krizhevsky, Sutskever, Hinton — ImageNet Classification with Deep Convolutional Neural Networks (2012).
Britannica — Deep learning (n.d.).
Linden, Smith, York — Amazon.com Recommendations: Item‑to‑Item Collaborative Filtering (2003).
Netflix — The Netflix Prize (2006).
Apple — iPhone 4S introduces Siri (2011).
Amazon — Echo and Alexa background (2014).
